









How to Become an AI Engineer in Brazil in 2026
By Irene Holden
Last Updated: April 10th 2026
Quick Summary
Sim - você pode se tornar AI Engineer no Brasil em 2026 montando uma pilha prática focada em Python, ML clássico, LLMs, MLOps e governança de dados, porque o trabalho hoje é orquestrar modelos e colocar soluções em produção. Escolha a trilha certa para você - seis meses intensivos com 20 a 25 horas semanais, 12 meses com 10 a 15 horas ou 24 meses com 8 a 10 horas, construa três a cinco projetos brasileiros e, se quiser acelerar, bootcamps como a Nucamp oferecem cursos de 16 a 25 semanas com valores entre R$ 10.620 e R$ 19.900 e relatam empregabilidade próxima de 78% num mercado aquecido por empresas como Nubank, iFood, PagSeguro e grandes escritórios de Amazon, Google e Microsoft em São Paulo.
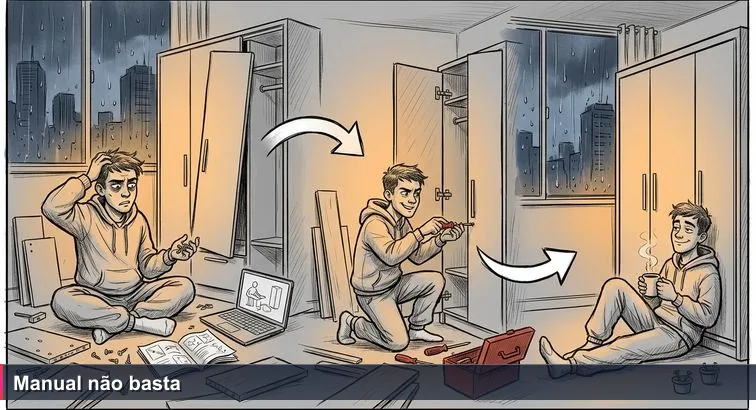
São 1h17 da manhã na Vila Mariana, chão tomado por MDF, parafusos sobrando e um guarda-roupa da Tok&Stok que insiste em ficar torto. O manual foi seguido à risca, o vídeo no notebook está pausado na mesma etapa, e ainda assim a porta emperra. A sensação é familiar para quem chega em casa depois do metrô lotado e pensa: “fiz tudo certo, por que não deu certo?”.
Muita gente em São Paulo, Campinas e BH vive a mesma cena com a carreira em IA. Abre um “AI Engineer Roadmap em 6 meses”, como os tutoriais tipo 6-Month Roadmap to Become an AI Engineer, segue a sequência Python → Álgebra Linear → Scikit-learn → PyTorch → Kaggle, fecha cursos, preenche certificados… e um ano depois ainda trava para montar sozinho um sistema de recomendação simples.
O problema não é você: é o manual incompleto. Guias globais como o AI Engineering Career Path Guide 2026 descrevem bem a pilha técnica, mas não contam que, no Brasil, o “piso” é torto: LGPD apertando, dados ruins, budgets curtos e vagas de AI Engineer recebendo 300-500 currículos por posição. Também não falam que a transição realista leva 6-8 meses para quem já é dev, e 12-24 meses para quem começa quase do zero, nem que engenheiros GenAI/LLM plenos relatam algo em torno de R$ 150 mil/ano aqui.
Entre o desenho perfeito do manual e o guarda-roupa firme no chão existe um conjunto de habilidades invisíveis: alinhar peça em piso torto, saber quando ignorar um passo, pegar a furadeira certa. Em IA isso vira: priorizar Python de produção e APIs acima de teoria exótica, escolher projetos que ataquem dores reais de fintechs e logística paulistas, lidar com LGPD desde o primeiro dataset.
Este guia assume que os roadmaps são só o começo. A proposta é tratar o “manual” como ferramenta - não como promessa mágica - e adicionar três camadas que quase ninguém mostra: contexto brasileiro, prática com “parafusos reais” em projetos end-to-end e feedback de quem já montou esse móvel em empresas como Nubank, iFood, Mercado Livre ou em startups de Campinas e Belo Horizonte.
Steps Overview
- Introdução: por que este manual é diferente
- Pré-requisitos e ferramentas mínimas
- Entenda o papel e escolha sua trilha de tempo
- Fundações: Python, computação e matemática aplicada
- Machine Learning clássico: algoritmos e boas práticas
- Deep Learning, LLMs e agentes: RAG e aplicações em PT-BR
- Engenharia de dados e MLOps: levar modelos à produção
- Portfólio com problemas brasileiros
- LGPD, ética e governança de IA
- Acelere com programas estruturados (incluindo Nucamp)
- Roadmaps mês a mês: roteiros de 6, 12 e 24 meses
- Verificação e troubleshooting: checklist e erros comuns
- Common Questions
Encontre no guia completo para iniciar carreira em IA no Brasil em 2026 uma comparação de formações, bootcamps e custos em reais.
Pré-requisitos e ferramentas mínimas
Antes de pensar em LLMs e agentes, é preciso nivelar o “piso do apartamento”: garantir que você tem o mínimo de base e de infraestrutura para que qualquer trilha de 6, 12 ou 24 meses seja sustentável. Roadmaps sérios, como os analisados no artigo da Nucamp sobre bootcamps com garantia de emprego no Brasil, assumem que esses fundamentos já existem.
Em termos de conhecimento, o ideal (não obrigatório) é sair do ensino médio com pelo menos:
- Álgebra básica: equações, funções, regra de três;
- Noções de gráficos e porcentagens para interpretar métricas de modelo;
- Alguma familiaridade com lógica de programação em qualquer linguagem.
No equipamento, o mínimo viável hoje é um notebook com pelo menos 8 GB de RAM (melhor ainda se tiver 16 GB) e SSD. Mesmo com máquina modesta, você consegue treinar muita coisa usando Google Colab ou Kaggle. Reserve também contas gratuitas em:
- GitHub (portfólio e controle de versão);
- Google Colab ou Kaggle (GPU gratuita limitada);
- Um provedor de cloud (AWS, Azure ou GCP, começando no free tier);
- Plataformas de curso como Alura Online de Machine Learning, Coursera ou Data Science Academy.
O recurso mais escasso, porém, é tempo. Para ter progresso realista:
- Trilha 6 meses (intensiva): cerca de 20-25h/semana;
- Trilha 12 meses (estruturada): 10-15h/semana;
- Trilha 24 meses (profunda): 8-10h/semana.
Dica prática: trate esse estudo como um segundo emprego. Defina dias e horários fixos (por exemplo, 2h pós-expediente + 4h no sábado), metas semanais claras (aula X + exercício Y + um mini-projeto) e use GitHub como “relatório de ponto”: se passaram 7 dias sem commit, o guarda-roupa está parado.
Entenda o papel e escolha sua trilha de tempo
Quando você abre uma vaga de AI Engineer em São Paulo, o texto parece manual de móvel: uma lista infinita de buzzwords. Mas, por trás disso, o trabalho mudou. Em vez de “inventar modelos do zero”, o foco hoje é orquestrar modelos já prontos (LLMs, APIs de cloud), conectar esses blocos a bancos de dados, filas, sistemas legados e cuidar para que tudo rode com segurança e dentro da LGPD. É essa visão pragmática que aparece em guias como o guia do The Pragmatic AI Engineer, muito citado em comunidades de carreira.
Antes de escolher a trilha, é crítico diferenciar seu alvo: AI Engineer não é pesquisador acadêmico que publica paper, nem apenas data scientist que faz análise exploratória. É o engenheiro que entrega sistema em produção: agente que chama API bancária, serviço de recomendação que escala na Black Friday, pipeline que treina e monitora modelos sem quebrar.
A escolha entre trilha de 6, 12 ou 24 meses depende menos de “vontade” e mais de ponto de partida. Em geral, quem já é dev back-end/mobile em SP, Campinas ou BH consegue encarar um plano intensivo de 6 meses; profissionais de engenharia, economia ou estatística costumam render melhor em uma trilha de 12 meses; quem vem de área totalmente diferente tende a precisar de algo mais profundo, em torno de 24 meses, com mais matemática e base de computação.
Para deixar isso concreto, vale olhar como programas estruturados organizam a carga: o Back End, SQL and DevOps with Python da Nucamp tem 16 semanas por R$ 10.620, o AI Essentials for Work roda por 15 semanas a R$ 17.910, e o Solo AI Tech Entrepreneur, mais completo, dura 25 semanas por R$ 19.900. Esses durações ajudam a calibrar a expectativa de tempo que você realmente precisa reservar.
O passo final aqui é simples, mas honesto: escrever quantas horas semanais cabem na sua rotina, quanto tempo você aceita levar para mudar de área, e então escolher uma única trilha para seguir. Ajustar a rota no meio é normal; pular aleatoriamente entre manuais é receita garantida para mais um guarda-roupa torto.
Fundações: Python, computação e matemática aplicada
Por que essas bases importam
Quase tudo que você fará como AI Engineer - de um modelo de churn em fintech até um agente com LLM - passa por Python e por um mínimo de matemática aplicada. Roadmaps sérios, como o guia de carreira da upGrad para AI Engineers, começam exatamente nesses fundamentos: código limpo, estruturas de dados, álgebra linear, probabilidade e cálculo básico.
O que dominar em Python
Seu objetivo aqui é sair do “copiar e colar” para escrever código de produção simples.
- Sintaxe, funções, módulos e classes;
- Entrada/saída de arquivos, consumo de APIs com requests;
- Bibliotecas para dados: numpy, pandas, matplotlib/seaborn;
- Um microframework web: FastAPI ou Flask para criar APIs.
Desde o começo, use Git e GitHub; isso antecipa práticas de times em SP, Campinas e BH.
Matemática aplicada na medida certa
Você não precisa virar pesquisador, mas precisa entender o que o gráfico de perda está dizendo. Foque em:
- Álgebra linear: vetores, matrizes, multiplicação de matrizes;
- Probabilidade e estatística: média, variância, distribuições, testes simples;
- Cálculo: derivadas univariadas e a ideia de gradiente descendente.
Boa parte dessa base pode ser feita em cursos introdutórios de universidades brasileiras ou em MOOCs internacionais.
Cursos, projeto prático e armadilhas
Um caminho enxuto é usar o bootcamp Back End, SQL and DevOps with Python da Nucamp: em 16 semanas e por R$ 10.620, você cobre Python, bancos de dados e DevOps, com resultados reportados de cerca de 78% de empregabilidade, 75% de graduação e nota 4,5/5 no Trustpilot (aprox. 398 reviews, sendo 80% cinco estrelas).
Seu projeto mínimo neste passo é um notebook de análise exploratória usando dados do IBGE, DATASUS ou dados abertos da Prefeitura de São Paulo, publicado no GitHub. Os erros clássicos aqui são três: só assistir aula sem digitar código, fugir totalmente da matemática e ignorar Git achando que “é cedo demais”.
Machine Learning clássico: algoritmos e boas práticas
Por que ML clássico ainda é o coração da brincadeira
Antes de falar em LLM, agente multi-etapas e LangChain, o mercado brasileiro ainda roda boa parte do faturamento em cima de Machine Learning clássico: crédito, fraude, churn, previsão de demanda, scoring interno. Roadmaps modernos, como o da Turing College para AI Engineers, continuam colocando regressão, árvores e métricas como núcleo obrigatório da formação.
Algoritmos e ciclo de ML que você precisa dominar
No mínimo, você deve ficar confortável com:
- Supervisionado: regressão linear e logística, árvores de decisão, Random Forest, XGBoost;
- Não supervisionado: k-means, clustering hierárquico, PCA;
- Métricas: accuracy, precision, recall, F1, AUC, especialmente em problemas desbalanceados.
Tão importante quanto o algoritmo é o ciclo de ML: separar treino/validação/teste, usar cross-validation, fazer tuning de hiperparâmetros e fugir de armadilhas como data leakage.
Stack de ferramentas e projetos “cara de Brasil”
Na prática, a combinação padrão será scikit-learn + pandas + numpy, com xgboost ou lightgbm para modelos tabulares mais fortes, e algo como MLflow para rastrear experimentos. Esses são exatamente os tipos de ferramentas listados em guias de “must-have machine learning skills” para engenheiros de IA.
Para treinar de verdade, fuja do Titanic e vá para casos que um recrutador de SP reconhece na hora:
- Modelo de churn para telecom ou SaaS brasileiro;
- Score de crédito simples para uma fintech fictícia (aprovado/não aprovado);
- Previsão de demanda para e-commerce nacional.
Boas práticas e armadilhas comuns
Nesta etapa, o erro clássico é se perder em detalhes matemáticos avançados e nunca fechar um pipeline end-to-end. Outro tropeço é confiar só em accuracy em datasets desbalanceados de fraude ou churn. Use desde cedo uma ferramenta como MLflow para versionar experimentos e anotar decisões; isso cria o hábito de trabalhar como os times de dados de São Paulo, Campinas e Belo Horizonte trabalham no dia a dia.
Deep Learning, LLMs e agentes: RAG e aplicações em PT-BR
Do “treinar do zero” a orquestrar modelos prontos
Nesta altura do jogo, Deep Learning e LLMs deixaram de ser “especialidade exótica” e viraram parte do dia a dia de quem constrói produtos em fintechs, logística e varejo. A grande virada é a commoditização de modelos: em vez de treinar tudo do zero, você passa a combinar APIs de LLM, embeddings e ferramentas externas para resolver fluxos inteiros.
"Model commoditization means your job is now effectively using APIs rather than training your own models."
Essa visão, defendida pelo autor do guia How To Become An AI Engineer in 2026, casa com o que executivos como Suzana Morais (Deloitte Brasil) vêm repetindo: o valor está em integrar GenAI à estratégia e a dados em tempo real, não em reinventar o transformer.
Deep Learning na medida certa
Seu objetivo aqui é entender o suficiente de redes neurais para não tratar LLM como magia. Foque em:
- Redes MLP para dados tabulares;
- CNNs básicas para visão;
- Um framework principal: PyTorch ou TensorFlow/Keras;
- Noções de overfitting, regularização e função de perda.
Guias como o roadmap de IA generativa para iniciantes da MSMGrad reforçam esse mix de fundamentos + prática com frameworks modernos.
LLMs, RAG e agentes em português
No mundo dos LLMs, você precisa dominar três blocos: consumo de modelos pré-treinados (via APIs ou Hugging Face), RAG (buscar contexto em bancos vetoriais antes de gerar resposta) e agentes que chamam ferramentas, APIs e bancos de dados.
- Embeddings e bancos vetoriais (Pinecone, Weaviate, alternativas open source);
- Frameworks de orquestração como LangChain e LangGraph;
- Cuidados especiais com LGPD e documentos em PT-BR.
Projetos e caminhos para aprender
Três projetos que “vendem” bem para recrutadores paulistas: chatbot de atendimento em português com RAG para e-commerce; assistente jurídico LGPD indexando a lei e políticas de privacidade; agente de operações de logística que consulta APIs de entrega e sugere ações. Bootcamps como o Solo AI Tech Entrepreneur da Nucamp são desenhados justamente para levar você de zero a produto SaaS com LLMs e agentes, enquanto programas intensivos como o Artificial Intelligence Engineering Bootcamp da Ironhack oferecem trilhas de 9 semanas full-time ou 24 semanas part-time focadas em projetos práticos.
Engenharia de dados e MLOps: levar modelos à produção
Por que engenharia de dados e MLOps decidem o jogo
Ter um modelo com AUC bonito no notebook é só metade da história. Em empresas como Nubank, iFood ou Mercado Livre, o que vale é fazer esse modelo rodar todo dia, em produção, sem cair na Black Friday e sem quebrar nenhuma regra da LGPD. Vagas de AI e ML em hubs como São Paulo e Campinas, mapeadas em portais como o levantamento de artificial intelligence jobs no Brasil da Built In, deixam claro que experiência com pipelines, deploy em cloud e monitoramento pesa tanto quanto “saber treinar modelo”.
Stack mínimo que um time em SP espera
Na prática, a caixinha “engenharia de dados + MLOps” costuma incluir:
- SQL avançado (joins complexos, window functions) e bancos como PostgreSQL ou BigQuery;
- Ferramentas de data pipeline: Spark ou Ray, e um orquestrador (Airflow ou similar);
- Containerização com Docker e noções de Kubernetes para escalar serviços;
- Monitoramento de modelos: logs, métricas de latência e métricas de negócio (churn, fraude evitada);
- Uso de plataformas de cloud como AWS SageMaker, Azure ML ou GCP Vertex AI.
Descrições de vagas como Lead ML Data Engineer em grandes fintechs brasileiras citam explicitamente essa mistura de engenharia de dados, ML e infra distribuída como requisito.
Projeto prático: API de previsão em produção
Seu “hello world” aqui é pegar um modelo que você já treinou (churn, crédito ou demanda) e:
- Empacotar em uma API com FastAPI ou Flask;
- Criar uma imagem Docker com o modelo e as dependências;
- Subir essa imagem em um serviço de cloud (Railway, Render, AWS ECS, GCP Cloud Run);
- Adicionar logging básico de requisições, tempo de resposta e erros.
O objetivo é ter uma URL pública que recebe JSON, responde previsão e pode ser testada por qualquer recrutador ou colega.
Erros comuns e como evitar
Os tropeços clássicos: ficar eternamente em notebooks sem aprender a expor um endpoint; ignorar logs e monitoramento (“funcionou uma vez, então está pronto”); fugir de cloud por medo de custo, em vez de usar free tiers e limites de gasto. Tratar este passo como engenharia de software “de verdade” - com versionamento, CI/CD simples e observabilidade - é o que aproxima seu portfólio da realidade dos times de dados em São Paulo, Campinas e Belo Horizonte.
Portfólio com problemas brasileiros
No mercado de IA em São Paulo, Campinas e BH, currículo sem portfólio é quase como falar que montou o guarda-roupa sem mandar foto. Recrutadores lidando com dezenas de candidatos por vaga usam o GitHub como filtro rápido: quem já resolveu problemas parecidos com os da empresa sai na frente. Plataformas de vagas como a lista de AI Engineer no Brasil na Wellfound mostram que praticamente todas as posições pedem “projects” ou “portfolio” de soluções reais.
O ponto não é ter dezenas de notebooks soltos, e sim poucos projetos end-to-end que contem uma história clara: problema de negócio brasileiro, dados (mesmo que simulados), modelo, avaliação e deploy mínimo. Para um tech lead em uma fintech da Faria Lima ou em uma healthtech de Belo Horizonte, isso vale muito mais do que mais um certificado de curso online.
Algumas ideias de projetos que “conversam” direto com o dia a dia das empresas locais:
- Fintech: score de risco de crédito com dados tabulares; modelo de probabilidade de inadimplência;
- E-commerce: sistema de recomendação simples para marketplace brasileiro, usando histórico de compras;
- Logística: estimativa de atraso de entrega para um app de delivery, com features de localização e horário;
- Varejo físico: previsão de demanda por loja/bairro em São Paulo a partir de séries temporais;
- Atendimento: classificador de chamados em português (prioridade/categoria) para uma SaaS B2B.
Para cada projeto, trate o repositório como produto: README explicando o problema, dados, arquitetura e como rodar; instruções de ambiente; um script de treinamento separado do notebook; e, se possível, um pequeno deploy (API, Streamlit, Gradio). Esse cuidado mostra maturidade de engenharia que empresas listadas em portais como as vagas de AI no Brasil na ZipRecruiter procuram quando falam em “production-ready solutions”, “scalable ML systems” ou “ownership end-to-end”.
LGPD, ética e governança de IA
Nenhum modelo em produção no Brasil existe fora da sombra da LGPD. Ela é o “piso torto” com que todo AI Engineer precisa aprender a conviver: não dá para simplesmente jogar dados de clientes em um bucket de cloud e sair treinando. Uma análise da ISG, citada em matéria da Yahoo Finance sobre projetos de IA no Brasil, resume bem o cenário: o valor da IA passou a depender de práticas disciplinadas de dados e governança, não só de modelos brilhantes.
Na prática, isso significa estudar três blocos ao mesmo tempo que aprende Python e ML:
- LGPD na prática: bases legais, consentimento, finalidade, minimização de dados, direitos do titular;
- Ética em IA: fairness (não discriminação em crédito, emprego, saúde), accountability, transparência;
- Governança técnica: anonimização/pseudonimização, trilhas de auditoria, logs, versionamento de modelos, model cards que descrevem limites e riscos.
Esses temas já saíram da teoria acadêmica: recrutadores em São Paulo e Campinas perguntam explicitamente como você trataria dados sensíveis em modelos de crédito, fraude ou saúde, e esperam ouvir algo além de “eu tiraria a coluna CPF”.
Para se aprofundar, vale combinar materiais da ANPD com cursos que discutem impacto social e regulatório da IA, como o oferecido pela UFMG sobre os impactos atuais da inteligência artificial, divulgado pelo Instituto de Estudos Avançados Transdisciplinares. Centros como USP/C4AI também produzem pesquisas em NLP para português que tocam diretamente em viés e responsabilidade algorítmica.
Seu projeto mínimo aqui é pegar um dos sistemas do seu portfólio - por exemplo um modelo de score de crédito ou um chatbot com RAG - e escrever uma página de governança: que dados pessoais entram, qual a base legal, quais riscos de privacidade e discriminação existem, e que medidas você tomaria (anonimização, limitação de propósito, explicabilidade, monitoramento de viés). Esse exercício simples o aproxima da forma como times de risco, jurídico e tecnologia vão avaliar seu trabalho em uma fintech da Faria Lima ou em uma healthtech de Belo Horizonte.
Acelere com programas estruturados (incluindo Nucamp)
Estudar IA sozinho funciona, mas costuma vir com o mesmo risco do manual de guarda-roupa: você segue tudo “no olho”, pula etapas sem perceber e descobre meses depois que faltou uma peça crítica. Em um mercado onde vagas de AI Engineer em São Paulo, Campinas e BH recebem centenas de currículos, programas estruturados encurtam esse caminho torto ao impor sequência, prazos e projetos obrigatórios.
É aqui que bootcamps como a Nucamp fazem diferença para quem está trocando de área. Com foco em acessibilidade, ela oferece trilhas de código e IA com mensalidades mais baixas que a média, parcelamento e workshops presenciais em mais de 200 cidades brasileiras. Os números falam alto: cerca de 78% de empregabilidade, algo em torno de 75% de conclusão e avaliação de aproximadamente 4,5/5 no Trustpilot, com perto de 398 reviews e 80% cinco estrelas.
| Programa Nucamp | Duração | Investimento | Foco principal |
|---|---|---|---|
| Back End, SQL and DevOps with Python | 16 semanas | R$ 10.620 | Python, bancos de dados, DevOps e cloud - base para ML/MLOps |
| AI Essentials for Work | 15 semanas | R$ 17.910 | IA prática no trabalho, engenharia de prompts, ferramentas como ChatGPT |
| Solo AI Tech Entrepreneur | 25 semanas | R$ 19.900 | Produtos SaaS com IA, LLMs, agentes e monetização |
Esses tempos e valores servem como régua para planejar sua transição: se um bootcamp completo leva de 15 a 25 semanas em ritmo guiado, tentar “virar AI Engineer em 8 semanas” estudando sozinho à noite é esperar milagre. Para quem busca caminhos acadêmicos mais longos, o panorama do ranking das melhores universidades de tecnologia no Brasil mostra opções como USP, Unicamp, UFMG, UFRJ, PUC-Rio, Insper e ITA alimentando o ecossistema de IA.
Além da Nucamp, há bootcamps presenciais e remotos como Ironhack São Paulo, e plataformas como Alura, Data Science Academy, Trybe e Ada Tech, todas com currículos pensados para empregabilidade. A chave é escolher uma rota compatível com sua disponibilidade de tempo e bolso, comprometer-se com um calendário claro e usar a estrutura como trilho: ela mantém o trem na linha enquanto você aprende a montar, testar e implantar soluções de IA que realmente funcionam no mercado brasileiro.
Roadmaps mês a mês: roteiros de 6, 12 e 24 meses
Até aqui você já sabe o que um AI Engineer faz e quanto tempo por semana consegue estudar. Agora falta transformar isso em um plano concreto de 6, 12 ou 24 meses. Esses roteiros não saíram da imaginação: eles condensam o que engenheiros relatam em threads como o “roadmap to becoming an AI engineer in 8-12 months”, ajustado à realidade brasileira.
Na trilha intensiva de 6 meses (para quem já é dev), o foco é fechar o ciclo completo o mais rápido possível:
- Mês 1: Python para dados, Git e análise exploratória (pandas, numpy, gráficos).
- Mês 2: ML clássico end-to-end (regressão, classificação, métricas, scikit-learn).
- Mês 3: Deep Learning básico (MLP, CNN simples em PyTorch/TensorFlow).
- Mês 4: LLMs, NLP em PT-BR, embeddings e um primeiro RAG simples.
- Mês 5: MLOps e deploy (FastAPI, Docker, cloud, monitoramento básico).
- Mês 6: Capstone brasileiro combinando ML + GenAI em problema real.
Na trilha de 12 meses, você expande a mesma jornada com mais tempo de base:
- Meses 1-3: lógica de programação, Python intermediário, Git e matemática aplicada;
- Meses 4-6: ML clássico, feature engineering, métricas e fairness;
- Meses 7-9: Deep Learning, NLP em português e uso de LLMs;
- Meses 10-12: SQL, pipelines, MLOps e um capstone end-to-end.
Na trilha de 24 meses, você aprofunda tudo: 1-6 em programação + matemática (álgebra, probabilidade, otimização), 7-12 em ML e Deep Learning, 13-16 em NLP/LLMs/RAG, 17-20 em engenharia de dados e MLOps avançado, e 21-24 em LGPD, ética, projeto avançado, escrita técnica e capstone.
Use esses roteiros como trilho, não como prisão. Ajuste temas entre meses conforme seu ritmo, mas mantenha a ordem geral: primeiro base, depois ML clássico, em seguida Deep/LLMs, e só então MLOps pesado. Empresas que contratam devs brasileiros para vagas globais, como descrito na análise da BEON sobre recrutamento tech no Brasil, esperam exatamente essa combinação progressiva de fundamentos + prática em produção.
Verificação e troubleshooting: checklist e erros comuns
Antes de se jogar em mais um curso, vale fazer a “vistoria final do guarda-roupa”: checar parafusos, portas e estabilidade. Esta seção é seu teste de sanidade: ela conecta tudo que você estudou com o que o mercado realmente cobra quando fala em “must-have machine learning skills” para engenheiros de IA, como descreve a análise da AI FWD sobre competências essenciais.
Checklist: você está pronto para trabalhar?
Use esta lista com brutal honestidade. Idealmente, a maioria das respostas deve ser “sim”:
- Python e dados: você pega um CSV qualquer, entende, limpa e gera insights em poucas horas.
- ML clássico: você monta um modelo de classificação/regressão do zero, explica a escolha, as métricas e os riscos.
- Deep Learning e LLMs: você já treinou ao menos uma rede neural e construiu uma aplicação com LLM (chatbot, sumarizador, classificador), incluindo ao menos uma POC de RAG com banco vetorial.
- MLOps básico: você tem pelo menos um modelo em produção, empacotado em API (FastAPI/Flask), rodando em algum serviço de cloud com logs e passo a passo de deploy.
- Portfólio brasileiro: há de 3 a 5 projetos no seu GitHub, bem documentados, reproduzíveis e conectados a domínios como fintech, e-commerce, logística, agronegócio, saúde ou aviação.
- LGPD e ética: você consegue explicar o básico da LGPD, como seus sistemas tratam dados pessoais e que riscos de privacidade/vieses foram mitigados.
- Autonomia: diante de uma nova demanda, você faz boas perguntas, modela o problema, escolhe uma abordagem técnica razoável e entrega um protótipo funcional em uma ou duas semanas.
Se algo falhou: troubleshooting da sua trilha
Cada “não” na lista aponta para um gargalo específico. Se falta deploy, volte à etapa de MLOps e priorize colocar um único modelo no ar, mesmo simples. Se o problema é LLM/RAG, recorte um caso mínimo (FAQ, base de documentos pequena) e foque em fechar essa POC antes de abrir outro curso. Se o buraco está em LGPD/ética, reserve algumas semanas para estudar regulação e reescrever a documentação dos seus projetos.
Por fim, trate o checklist como item recorrente: repita a cada 3-6 meses. Isso força você a sair do modo “consumir conteúdo” e entrar no modo “entregar sistemas”, que é exatamente o que times de engenharia em São Paulo, Campinas e Belo Horizonte esperam de alguém com título de AI Engineer.
Common Questions
Consigo me tornar AI Engineer no Brasil até 2026? Em quanto tempo isso é realista?
Sim - é realista, mas depende do seu ponto de partida: trilhas intensivas de 6 meses (20-25h/semana) funcionam para desenvolvedores já experientes; 12 meses (10-15h/semana) para quem tem alguma base; e 24 meses (8-10h/semana) para iniciantes completos. Seja realista: vagas competitivas em 2026 podem receber 300-500 currículos, então ritmo, projetos práticos e portfólio contam tanto quanto cursos.
Quanto vou gastar com cursos, ferramentas e equipamento para começar?
Equipamento mínimo: notebook com 8-16 GB de RAM e SSD; internet estável; contas gratuitas em GitHub e Colab/Kaggle; cloud no free tier (AWS/GCP/Azure). Em cursos, bootcamps brasileiros citados custam entre ~R$10.620 (Nucamp Back End) e R$19.900 (Solo AI), mas você também pode combinar materiais gratuitos e cursos pontuais para reduzir custos.
Já sou desenvolvedor em São Paulo/ Campinas - qual trilha devo escolher para virar AI Engineer?
Se você já programa e conhece APIs/Git, a trilha intensa de 6 meses é a mais indicada, focando Python de produção, MLOps (Docker/K8s), RAG/LLMs e deploys. Isso alinha seu perfil com vagas em empresas locais como Nubank, iFood, PagSeguro, VTEX e times de AWS/GCP/Google em SP.
Como lido na prática com LGPD e dados ruins em projetos de IA no Brasil?
Trate LGPD (lei aprovada em 2018 e em vigor desde 2020) desde o design: documente bases legais, minimize coleta, anonimize quando possível e mantenha trilhas de auditoria. No nível técnico, implemente anonimização/agregação, testes de viés e um model card por projeto para evidenciar mitigação e conformidade.
Que projetos devo ter no portfólio para ser notado por fintechs e big techs em São Paulo?
Tenha 3-5 projetos end-to-end: ao menos um modelo clássico (churn/crédito) com deploy público (API), um projeto com LLM/RAG em PT-BR e um exemplo de MLOps/pipeline com logs e instruções. Documente tudo no GitHub (README claro, arquitetura e instruções de execução) e destaque como tratou LGPD e monitoramento.
Este post compara os top incubators and coworking spaces in Brazil 2026 e destaca oportunidades em São Paulo, Belo Horizonte e Florianópolis.
Quer entrar em tech rápido? Confira os top empregos de tecnologia no Brasil 2026 que priorizam skills e portfólio.
Se quer comparar ofertas, leia nosso ranking das top empresas que mais pagam no Brasil em 2026 para carreiras em IA e dados.
Compare oportunidades lendo o Top 10 companies hiring AI engineers in Brazil in 2026, com stacks, salários e hubs locais.
Os 10 melhores bootcamps de IA no Brasil em 2026 - escolha por região

Irene Holden
Operations Manager
Former Microsoft Education and Learning Futures Group team member, Irene now oversees instructors at Nucamp while writing about everything tech - from careers to coding bootcamps.